Description du projet
Ce projet est un outil complet de scraping web et d'analyse de données utilisant Python, BeautifulSoup, pandas, Matplotlib et MySQL. Il permet de récupérer, stocker, analyser et visualiser des données produits à partir de sites e-commerce : cas de Books to Scrape(Site de ventre de livres).
Fonctionnalités principales
- ✅ Scraping Web (nom, prix, catégorie, avis, lien vers les livres)
- ✅ Stockage dans une base MySQL
- ✅ Nettoyage & enrichissement des données
- ✅ Visualisation via matplotlib / seaborn
- ✅ Export CSV
Accéder au code source du projet :
Installation
1. Cloner le dépôt
git clone https://github.com/Ross260/SPRINT_DATA_FINAL_PROJET.git2. Installer les dépendances
pip install -r requirements.txt3. Créer la base de données
CREATE DATABASE ecommerce_scraping;
USE ecommerce_scraping;
CREATE TABLE produits (
id INT AUTO_INCREMENT PRIMARY KEY,
nom VARCHAR(255),
prix DECIMAL(10,2),
categorie VARCHAR(255),
avis VARCHAR(50),
lien TEXT
);
4. Configuration de connexion
Dans le fichier config.py :
DB_CONFIG = {
"host": "localhost",
"user": "hostname",
"password": "your_password",
"database": "ecommerce_scraping"
}
Utilisation & Résultats
Lancer le scraping
python main.pyAperçu de la base de données après exécution du script
Après exécution du script, un premier filtrage des données est appliqué avant le stockage en base de donnée
Nettoyage des données
python nettoyage.pyAperçu des premières ligne du dataframe après exécution du script:

Après exécution du script, les données sont récupérer en base de données, néttoyées et dans le but de rendre les donnée pertinente pour l'analyse, des colonnes sont ajouter au dataframe et ensuite il y a un stockage en CSV
Visualisation
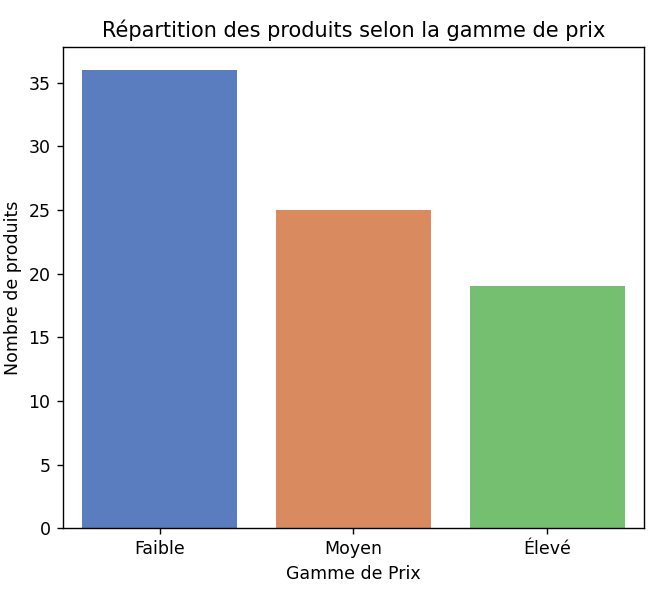
- 📈 Répartition des prix
- 📊 Produits par catégorie
- 🔎 Corrélation prix / avis
- ⏳ Évolution des prix
Générer les graphiques de visualisation :
python visualisation.py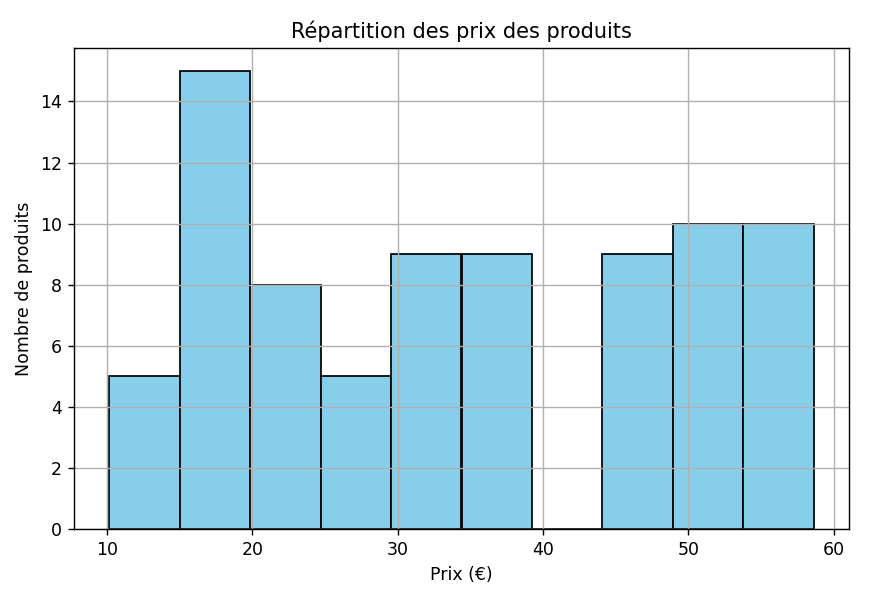
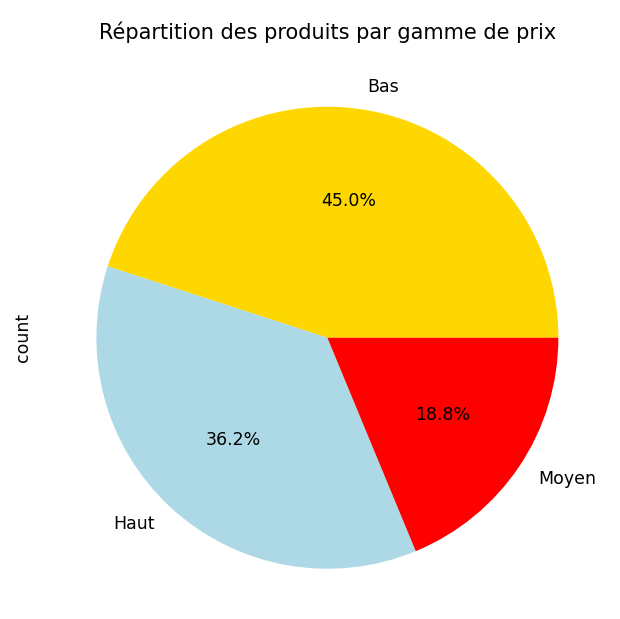
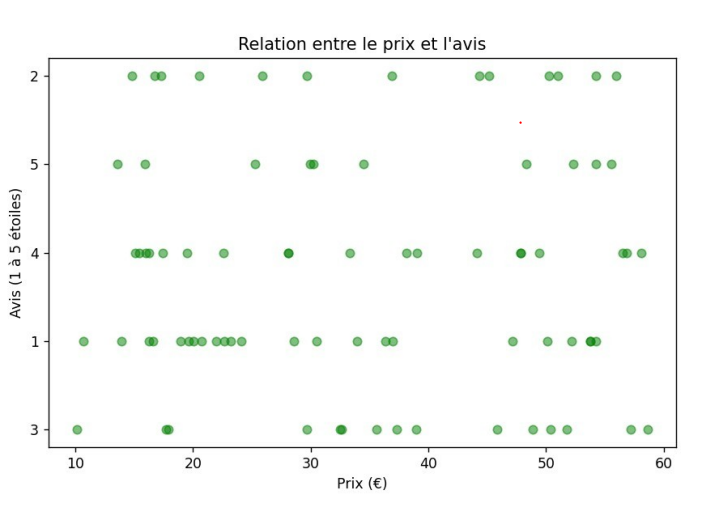
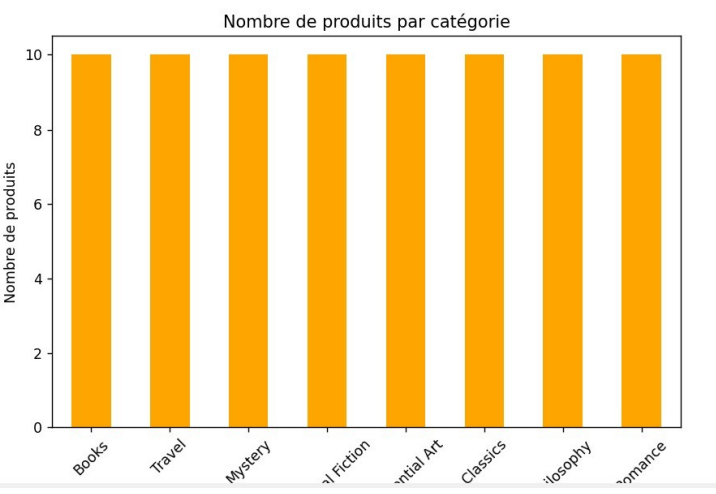
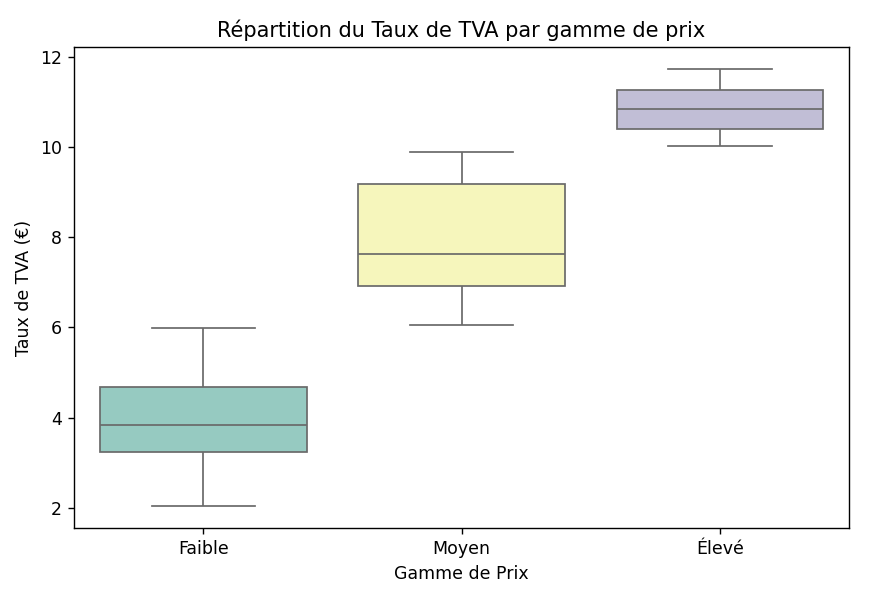
Analyse sur les gammes de prix